 contact :
contact : How does perplexity rank content ?
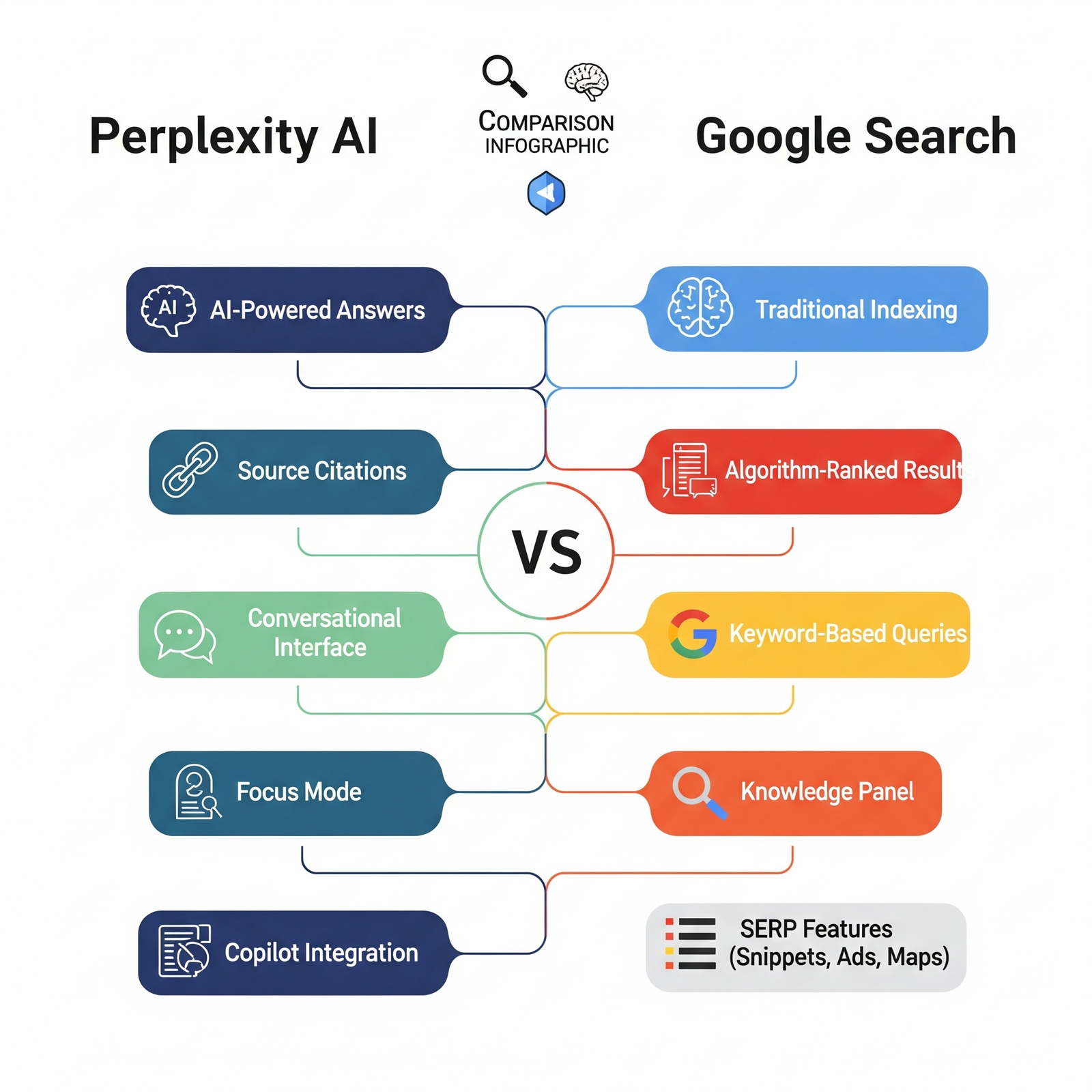
With the new world we are in where search has diversified drastically from traditional search patterns. We have done this before, adapt to the market evolution when the alexa and siri launched to optimize for voice search. SEO is a continuously evolving field and it is an exciting time to be in. With the rise of AI , we are seeing people consume results through AI like Perplexity, Gemini, Copilot, Claude. Let’s look at Perplexity today with the humungous growth in the past couple of months, as on today the early August of 2025. Their potential traffic stands at 20 million users per month. Here is a breakdown of their growth.
How does perplexity work :
Perplexity ranks and cites content based on semantic relevance, authority/trust, freshness, structure/clarity, and user engagement, with an additional ML-based reranking layer that can drop sources that don’t meet quality thresholds.
Ranking Factors : What’s known from recent analyses and industry reporting
Retrieval + reranking pipeline: Initial retrieval favors semantically relevant pages (often overlapping with top Google results), then an ML “L3” reranker applies stricter quality thresholds; pages can be completely dropped if they don’t meet minimum scores.
Authority and “trusted domains”: Perplexity gives extra weight to well-established, high-trust domains (e.g., large marketplaces, developer hubs, Wikipedia, major media, Reddit for UGC context) and overall domain reputation over single-page signals.
Semantic intent matching: Content that directly answers the full user intent, covers related sub-questions, and uses natural language with strong topical depth ranks better than keyword-stuffed pages.
Freshness and recency: Recently updated pages and topics with timely signals get preference; visible “last updated” helps.
Structure and extractability: Clear headings, answer-first writing, bullet lists, tables, FAQs, and schema (e.g., FAQPage/HowTo JSON‑LD) make it easier for LLMs to extract and cite.
User signals and early performance: Early click-through/engagement after publishing can influence long-term visibility; new-post thresholds and decay windows were observed in telemetry-style research.
Topic/category multipliers: Some topics (AI, tech, science, business) appear to receive algorithmic boosts vs. entertainment/sports, per recent reverse-engineering posts.
Indexing dependencies: Coverage correlates with Bing/IndexNow and general SEO health; content that isn’t indexed well struggles to appear.

SO how to rank on perplexity
Make answers extractable:
Lead with a direct, one‑sentence answer under each H2/H3; follow with concise explanation
Use Q&A blocks, bullets, tables for comparisons, and include definitional snippets.
Optimize semantic depth:
Cover related sub-questions, definitions, caveats, and alternatives in one page. Vary vocabulary and include closely related entities/terms naturally.
Strengthen authority:
Earn citations/mentions from respected publications, Wikipedia-adjacent references, industry “best of” lists, high-quality backlinks, and credible UGC where relevant.
Keep content fresh:
Update high-intent pages regularly; display “last updated”; add new data points and recent examples.
Technical and schema hygiene:
Ensure fast, mobile-friendly pages with clean robots.txt, XML sitemaps, canonical tags; implement JSON‑LD (FAQPage, HowTo, Product, Article).
Ensure discoverability:
Use IndexNow/Bing submission; verify Bing indexing for key URLs; maintain internal linking and content clusters to signal topical authority.
Launch and monitor:
Promote new content to drive early CTR and engagement during the “new post” window; watch dwell time and refine headlines/meta to improve click and retention.
Here is one video that gives you similar context on the topic.